Like my 3B term and 4A term recap, I’m gonna do the same for my 4B term experiences - especially since it’s my last term of undergrad! WAHOOO! 👨🎓🎊
So here you go. My term-end reflection:
Note: again, this will be a long post so hold tight. I feel like 4b contents are definitely very dense. And I do wanna take this opportunity to just review / reteach my understandings (for my future self potentially). In fact, I do find myself learning a lot while summarizing.
Table of Contents
- Programming for Performance - ECE 459
- Autonomous Vehicle - ECE 495
- Astronomy - SCI 238
- Quantum Mechanics - ECE 405
- Capstone Design Project - ECE 498B
- What’s next?
1. Programming for Performance - ECE 459
So glad I took this course. Learned Rust on top of performance for programming, which a lot of people dislikes, but I think I’d prefer Rust over C/C++. It takes a long time to get it to compile, but once it does you can almost guarantee there’s no memory leaks or something ugly during runtime.
The assignments were super hands-on and useful. But the final was brutal! (stayed up till 6am until I finally gave up 😞)
My main key takeaway from the course: ‘Don’t guess; measure’.
Generally some other good advices I quote from the lecture notes: - Understand the order of magnitudes that matter (know what performance is considered acceptible) - Plan for worst case (e.g. a user that opens too much apps) - Performance should be a culture (team effort rather than individuals). E.g. should be integrated in the build process (like a regression test that runs overnight), and are tracked. - Throws me back to a few of my earlier coops. At IBM, I remembered one morning where I saw the senior devs sitting together all trying to trace a memory leak in the program. In LD, I also perform gatling tests for performance (which I think could’ve been automated), and I also build live graphs from stackdriver logs of the system to track telemetries from our servers. - Do things you’re best at. Outsource the rest. - Human adventure is just the beginning :)
A) Rust
One unique thing about Rust is the concept of ownership. When passing a variable as argument you’re handing over ownership of that variable to the invoked function, and you can’t access it anymore. Another thing you could do is to use the borrow operator ‘&’, which guarantees that the data will be available to the caller once the method ends. Another alternative is to just clone it. But the idea is that there can only exist one owner at a time - this allows compile-time GC! (You don’t get performance penalty of deallocation during runtime, and also eliminates memory leak).
It’s not always flowers and rainbows though. I think explicitly having to manipulate data lifetimes to tell the compiler certain things, or using unsafe block - are stuff that seems daunting and ugly. Packing everything in Option/Result and having to .unwrap() everything to use it seems pretty annoying as well, but I’m sure it makes error handling much cleaner (actually prefer this than Go’s error handling). It takes time to get the code up and running, but when it does I generally feel pretty good about my code 😎.
B) Asynchronous I/O, multithreading, proceses
Parallelization is always a low-hanging fruit to leverage when it comes to speeding up program (as long as tasks are independent and when its benefits outweigh the overheads). I learned to use shared mutex and message passing for inter-thread communication (which are reviews from past OS course). There was also an assignment where we used libcurl multi, for its non-blocking interface. In the first few assignments, we distribute a long-running work across multiple threads, which should be straight forward… except that Rust can be frustrating to work with at times.
Processes on the other hand, are safer (has its own memory address space) but more heavy-weight than threads (IPC has system call overheads).
C) Compiler and the CPU
I just hope that I don’t have to touch this, ever. But there are some niche stuff going on in the compilers and processors. To name a few, there are caching (branch prediction and maintaining cache consistency between multiple CPUs), speculation (ie. precomputing certain tasks to save time), compiler and hardware can re-order your code to execute them in an order that’s most convenient, inlining (remove function call overhead but if misused may affect cache hits, size, etc), and many other compiler optimizations that speeds your code behind the scenes. The good news is I believe most of these stuff should be abstracted away from normies like me in my day-to-day programming tasks. I trust that my compilers are smart.
D) Flamegraph
Flamegraph is just a top-tier profiling tool ✨. It identifies where to improve the code for performance, rather than simply ‘guessing’. In the assignment for example, initializing iterators and backoffs from message-passing channels are way more expensive compared to the I/O (who would’ve known if it wasn’t for Flamegraphs!). It was also a pretty fun activity to try different methods and see if it could improve the runitme (or slow it down 😢).
Aside: In fact, React also had their own flamegraph profiler on the browser. Gonna try this out sometime..
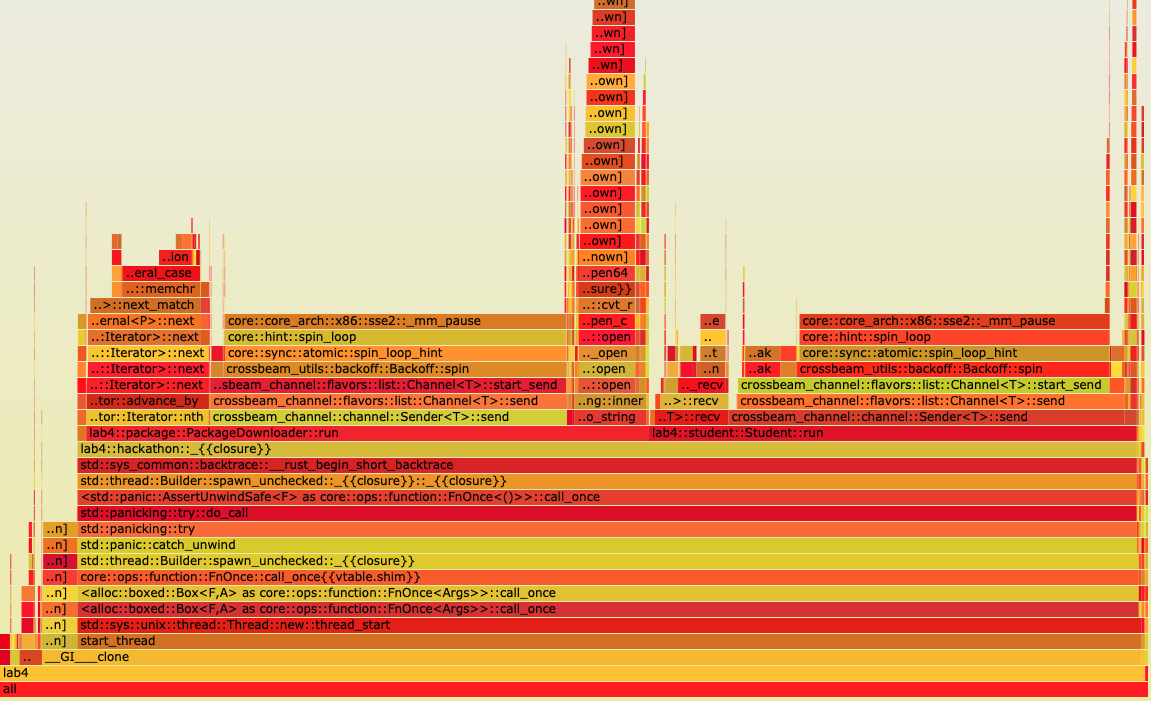
Not to mention a lot of other profiling tools like Valgrind (analyze memory allocations), Helgrind (concurrency problems), which I’m guessing is more relevant for C/C++ programs. There’s also linux’s ‘perf’ tool that gives general stats as well as costs per line of code.
E) GPU Programming
It was a humbling experience to get to code in a GPU (with CUDA). Basically, one would first copy over the data to the GPU device (we used RustaCUDA interface in Rust), wait while the kernel (our CUDA code) executes, and then the results are transferred back to memory.
In the assignments (and final), we leverage them to perform data parallism (distribute work-items over the thousands of GPU threads available). For example, to perform matrix multiplication, rendering, counting votes, etc.
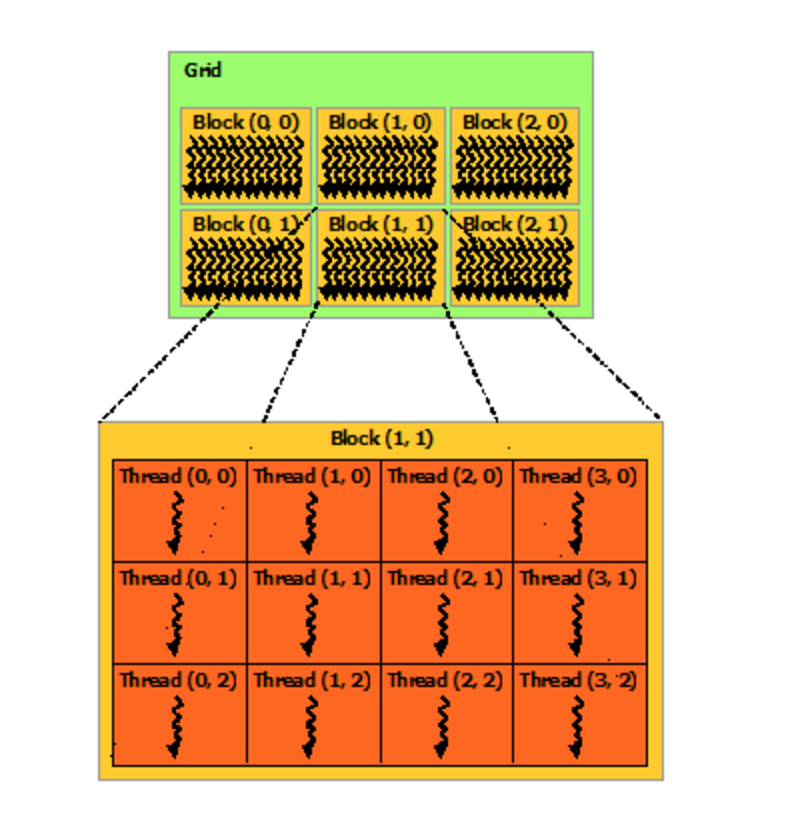
CUDA code is a new paradigm to me. The global cuda function called by the host will be executed by multiple independent cuda threads. From what I understood (stackoverflow), the pointer arguments copied from the host will be located in device as a ‘global memory’ and shared amongst all cuda threads. So coding in cuda, I make sure not to write to the same memory output (e.g. each thread writes to its dedicated indices on an output matrix). To tell which thread does which work, normally involves using the set of indexes uniquely available to the current thread (threadIdx.x, blockIdx.x, blockDim.x, etc). The indices come from the landscape of the cuda threads, which are partitioned into 2D constructs called blocks and each blocks are partitioned in a 2D construct called a grid. We are free to define the block & grid sizes in the host code (within limits). In particular this diagram below helps me a lot when visualizing the gpu thread landscape: (image source: Nvidia docs). In that example, our grid size is (2x3), block size is (3x4), and thus 12 * 6 = 72 gpu threads in total.
I was able to get away with just using global and private memory throughout the course, but apparently there’s also other types of memory like shared memory which one could leverage.
Otherwise, CUDA code itself looks to me like standard C-code, with some hardware caveats to be aware of such as that branch conditions is useless (hardware will execute all branches even if we don’t enter them).
F) Scaling, queuing theory, Ops
When you can’t speed up, just spend 💰 and scale. However testing could now become harder (e.g. test multiple machines), and sometimes you must simulate pressure to begin seeing things blow up 💣. Potential culprits could be the CPU, memory usage, network, etc. You gotta figure out what’s limiting your system 🕵️♂️🔎.
Queuing theory also provides another set of toolbox to numerically answer interesting questions like how much more hardware we’d need to satisfy an increase in traffic, what’s the max # of users we can support, etc.
There was a few notes on Ops that I think was worth the reminder. One of which is to treat ‘configuration as code’ - to avoid human mistakes of installing complex dependencies, setting up, and you get to version control it. Containers are one approach but you need to remember to upgrade things frequently for security reasons (which is not enforced in docker).
Final Words from me 🧖♂️
Overall I think this was a good touch on PfP. I’m more aware of the things that I could be doing to identify performance bottlenecks in my code. On an aside, one book that has been on my read list since my time at LD internship was the Google SRE book. Would love to learn more on how performance is monitored and maintained in a production software.
2. Autonomous Vehicles - ECE 495
This was a fun course! It breaks the whole niche into comprehensible parts, rather than the rocket science I thought it will be (although it did get extremely difficult near the end when we talk about vehicle controls).
Humble brag: Got 100 in my final grade. Seems kinda sketchy, but I swear I made some mistakes in the midterms (and potentially finals). There were some bonus marks on submitting assignments early, or maybe he curve the exam? 👀 Anyways this was a first and potentially last time 😆
We begun by understanding different levels of automation, typical sensors, what they do, and why it’s needed (gps, IMU, wheel odometry, camera, lidar, radars, map..), and functional architecture of a typical automated driving system. The 3 main parts of the system architecture are ‘perception’, ‘decision making’, and ‘control’.
A) Computer Vision Fundamentals
- Color representations (e.g. RGB, HSV - better at differentiating hue colors, YCbCr - better for compression)
- Image filtering: using cross-correlation/convolution to apply filter/kernels to an image. They can be linear filters (e.g. sharpening filter, gaussian blur filter, finding certain patterns), or non-linear (e.g. thresholding to create binary mask over color of interest, morphological filtering, bilateral filtering).
B) Traditional Computer Vision to detect low-level features (like edges, lines, points) - To detect edges, we could take the derivative along x & y axis. A high magnitude of derivative means there’s a rapid change in intensity (edge). Derivative could also be taken using a linear filter/kernel. (a commonly used filter is the ‘Sobel filter’). - Canny Edge Detection: A general method to get clean edges. The steps are: 1. grayscale the image, and smooth using gaussian blur (reduce noise) 2. Use sobel filter to get the magnitude of lines 3. Non-max supression: Reduce edges to a fine thin line. For each pixel, set its value to 0 if there’s a neighboring pixel along a discrete orientation with higher magnitude. 4. Double-thresholding: remove unconnected weak edges and keep strong
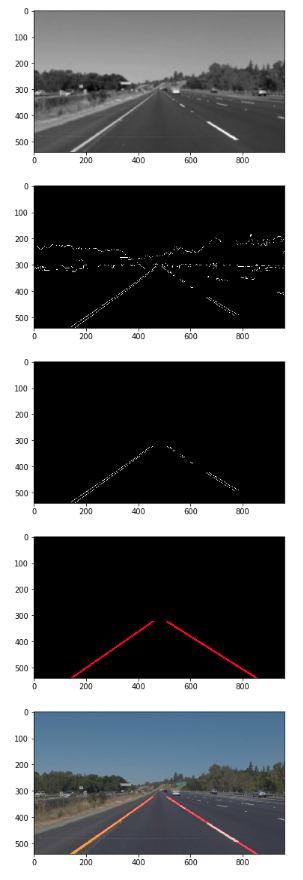
In the assignment, we create a pipeline to detect road lines from a video (as shown on image above). The starter code is actually from Udacity. After masking a trapezoid region of interest (ROI), implementing Canny Edge to obtain the edges, I used ‘Hough Transform’ to parameterize the lines (map the x,y pixels to a Hough space and vote for the max overlaps of d, θ). Once we get the line equation (d = xcos(theta) - ysin(theta)), we draw the solid lanes for that frame.
Generally, hand-coding algorithms with first principles is good enough for low-level classification (ie. edges/dots). But for high-level semantic labels (ie. bicycle, cats), using ML makes it possible to identify more complex variations by learning the solution from ‘data’. ML can also fail in spectacular ways, which is scary especially for these critical systems.
C) ML - Linear Regression
A basic loss function to optimize/minimize is ‘least squares estimate’ (the weights are the slope and bias). For simple linear regression, we could even use closed-form solution (ie. solve w from the first derivative of the cost function) - this involves inversing matrix which may be expensive/impossible for large data. Alternatively, gotta use gradient descent.
RANSAC - used to remove outliers. The idea is simply to iteratively trial/error by first sampling a subset s (smaller the better) from all the points, fit the model with the subset, see how it performs (ie. count # of inlier points from the entire subset), repeat, and at the end use the subset of points that has the most agreement (aka. least outlier points). A cool applications using RANSAC is the 5-point algorithm in visual odometry (making sense of 3d space using camera images), stitching points (homography) from 2 references of the same object, generating lidar localization maps, etc.
D) ML - Classification
- Like linear regression, binary classification deals with learning a function, but is non-linear and used to split different classes. A typical function is the logistic/sigmoid function (smoothly go from 0 to 1 which maps nicely to probability values of being in a class). We have 2 parameters to train (one scales and one bias/moves the function left/right).
- To train logistic function, use cross-entropy as the loss function and minimize that. Given a point, the cross-entropy loss would be -ln(predicted probabilty of true label). The negative log likelihood or entropy is like the random variable result’s ‘surprise’ factor (If it’s correct then we’re not too surprised). The total loss would be sum of losses for all points.
- Once we have the total loss function, we use ‘gradient descent’ to incrementally lead the weights to minimize the loss (for each trainable weights, you subtract it with the derivative of loss function wrt that weight, to go in direction of steepest descent).
- The idea extends to multivariable logistic functions (classify based on multiple features). This turns our logistic function to multidimensional (> 2D) (n features and 1 output).
- This extends to multi-class/multinomial logistic regression (classify > 2 classes). But instead of sigmoid, we use softmax (a generalization of sigmoid). Softmax accepts the logits (dot product Wx) and returns the probability of each k classes (whereas sigmoid returns the probability for a 2-class bernoulli distribution). We still use cross-entropy to train the weights so that it minimizes the loss function over this softmax function.
E) ML - Neural Network
While linear/logistic regression approximate a function to fit the data and produce desired labels, a NN is like a generalization when you have multiple layers of function/transformation to get the labels (edge is the weight, and nodes are the scalar logits). The nonlinear activation functions (e.g. softmax, reLU, sigmoid..) graphically tweaks the landscape of our function approximators, and adding new layers creates more complex landscape (analyzing topology provide cool graphical insights of NN).
The idea is still the same though - feed data, score the output on a loss function, optimize the parameters with gradient descent. However, recall that gradient descent update requires calculating first derivative (slope) of the loss function wrt the weights. This is more challanging since weights are distributed over many layers, so the approach is to backpropagate the loss from the output to every weights in previous layers. Doing numerically might be slow, so there’s actually ‘automatic differentiation’ that remembers intermediate values as you pass.
Since backpropagation is expensive, a typical batch gradient descent training typically takes the average loss over all input data and backpropagate that average for the entire data batch. Analyzing the error, you realize that as size of the batch N increase, we get diminishing returns. That’s why we normally do ‘Stochastic(minibatch) gradient descent SGD’ which is like a normal GD, but we shuffle and sample a small subest of the training batch at each iteration. There are also optimization algorithms for SGD (ie. adam, momentum..) to hopefully improve convergence (trial/error approach).
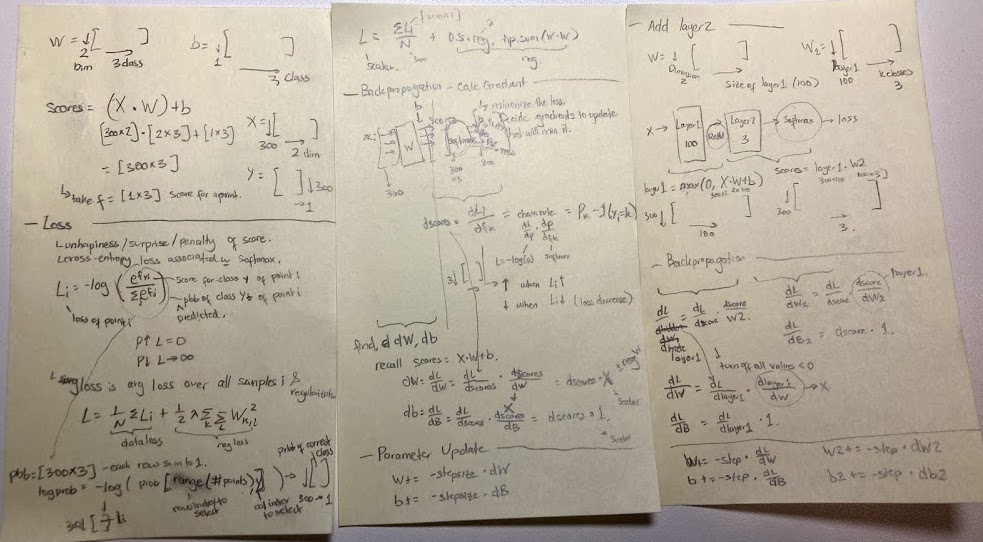
- Things begin to click for me as I was doing the assignment, which was to hand-code a simple feed-forward and backward-pass on 2 layer fully connected NN (input layer -> FC layer -> ReLU -> FC layer -> softmax). Image above show my messy 2-layer backpropagation formulation notes.
F) Deeper into DNN: Improving model
- Design considerations to improve NN model:
- Decide train-validation-test splits
- Deal with underfit (when train loss is high, maybe try changing architecture, or add more layers to make it smarter) or overfit (when train loss is good but don’t generalize to unseen data. Try add regularization to make it dumber, like adding L2 norm on our loss function to penalize complexity of large weights, dropout, or early stopping)
- normalizing our inputs before feeding it into the NN to improve loss landscape (‘batch norm’ takes this further and normalize inputs for hidden layers).
- Breakthroughts typically comes in improvement of the network architecutre.
- CNN layer: Unlike fully connected, sometimes we just want a subset of features. So the dot product occurs for a subset of all inputs (receptive field), same way as a convolution would. The output is a ‘feature map’. A ConvLayer typically define a number of kernels (the channels / depth) which is computed independently (e.g. 3 channels to calculate RGB color channels).
- pooling layer: reduce feature map using aggregation (ie. max/avg pooling). This makes the output less sensitive to the receptive fields / variations in the input.
- Downsampling / Feature extractor: is what we call the beginning layers which extract low-level features rather than task-specific. Typically has small W & H (large receptive field) and high depth (many features), and is reusable for many tasks. (Examples are VGG, ResNet, Densenet..)
- Upsampling / feature decoder: from our feature extractor, we want to upsample our output to convert it back to the correct size/resolution. (many methods like ‘transposed convolution’. Trial/error.)
- Skip connections: To improve loss landscape (solves vanishing gradient), we can connect earlier layers as input to later layers (connection can either be elementwise additive or concatenation).
- CNN layer: Unlike fully connected, sometimes we just want a subset of features. So the dot product occurs for a subset of all inputs (receptive field), same way as a convolution would. The output is a ‘feature map’. A ConvLayer typically define a number of kernels (the channels / depth) which is computed independently (e.g. 3 channels to calculate RGB color channels).
G) Deeper into DNN: Semantic segmentation
- Using downsample-upsample approach. We could represent our DNN output as a one-hot-encoding of the segmented classes (so output volume shape is W x H x #classes), compare that with our annotations (loss), and perform cross-entropy.
- The many segmentation architectures include Segnet, U-net, PSPNet, HRNET, and many more in development. It was quite interesting to see different approaches and justifications. For example the U-net use skip-connections connecting layers in feature extractor with upsampling layers, so that decoder have access to different abstraction layers of the lower-level features - potentially helping to segment objects at different scales/sizes. Another approach in PSPNet is using feature pyramid (downsample at different scales, process them separately and then combine). The recent 2020 paper HRNet step this further by generating different resolutions in stages.
- In one of the assignments, we build a semantic segmentation NN based on a given encoder-decoder architecture. Although most of the job was already done in the startup code (ie. training loop, data loading, displaying, etc), the goal was simply to get a hands-on with defining different types of layers in pytorch (ie. dropout, batchnorm, skipconnections..).
H) Deeper into DNN: Object detectors (draw bounding box over an object) - We could take the downsampled features, pass them over to ‘auxiliary layers’ (downsample even further to ensure higher receptive field), and use anchor boxes (potential locations, size, aspect ratio to place the bounding boxes) and the output layer will predict for each bounding box if it belongs to the classes we try to detect. - The output would be a volume with i & j (width/height) corresponding to the grid of anchor points, and k-vector (depth) will fill in the information needed to predict the box variations for that anchor point (ie. Δx-y translations, Δw-h of the boxes, and the n+1 probabilities for predicting the n classes + background) 🤯. So as far as this goes, we’re able to parameterize everything that we needed and this becomes like a classification problem. - At inference, use NMS (non-max filtering) algorithm to remove bounding boxes that aren’t important or a duplicate - so we end up with only the important boxes that have a high enough score/confidence. - Our assignment on object detector was based on a Pytorch tutorial on github. We just had to fill in certain parts of the code like loading the extractor ResNet model (transfer learning setup), and few questions on the NMS implementation. Most stuff is done for us, and it’s interesting to see how loss were calculated since we’re essentially optimizing multiple parameters together. - For object detection / segmentation, the metric to evaluate the model is usually IOU (how much prediction intersect with ground truth), and average precision (mAP).
I) State estimation - Idea: sensors are noisy in real world, so we need to combine our ‘dynamic state model’ (system state prediction) with a ‘measurement model’ to give us the best estimate of the current system state. - The state-space model consist of measurement and a state update equation. Equations can be of many types (linear/non-linear, time-invariant/time-variant, continuous/discrete). - Alternatively, state space models could be represented as ‘probabilistic dynamic models’ (using conditional probability distributions, instead of a function). - e.g. model: ‘Dynamic Bayesian Networks’. Such models can make it easy to probabilistically determine the output over multiple iterations and inputs, by defining the left stochastic matrices which summarize transitions in a bayesian network (each node is a r.v. and the edges are conditional influence P(output | inputs)). - Once we define the models, we can use state estimation algorithms like ‘bayes filter algorithm’ for discrete systems, or ‘kalman filter’ for continuous time systems with additive gaussian noise, or some other filters like ‘EKF’ if its non-linear (also need different filters depending on noise distributions). - in general bayes filter/kalman is a 2 step process. First, generate a ‘belief’ of current state using previous state and action. Second, update the state using that belief with the measurement. - Recall ‘bayes rule’: Posterior = (likelihood * prior)/evidence - Applications: Occupancy grid - The state is probability of each cell being occupied. The 2 step bayes filter generated a best estimate of the value of each cell, as the robot scans multiple times. - Bayes filter update is made easier with using logits instead of probability as the state. Using logits, multiplying probabilities turn into addition, and our range becomes more workable for really small/high probabilities. - During the assignment one cool algorithm that caught my eye was the Bresenham’s algorithm (to capture the grid cells that’s covered by a line quickly).
J) Vehicle Control & Motion Planning
The last few part of the course was blurry to me. It was partially a review for my robotics course ECE486 last term and other control theory in earlier terms (which I barely remember 😗).
- Kinematic modeling: simply focus on movement geometry (e.g. modeling a bicycle in 2D involves yaw rate, angle of steering, etc).
- Dynamic modeling: consider inertia, mass, balancing the force equations, powertrain modeling… These are more accurate at higher speeds but man does these equations go crazyyy…
- to follow a path, we need to compute the steering inputs. This is done by measuring error from the reference path, and adjusting the inputs. (e.g. by using pure pursuit, MPC, PID controllers).
Our 8th assignment was cool though. We did behavioral planning (code a FSM to decide how the vehicle should change lanes, given data like the ego’s position and distances from other vehicles around it). The goal is to complete 2 miles of driving while avoiding collisions and completing it within 3 minutes. The whole thing was based on Udacity’s Nanodegree course since they provide a really good driving simulation. The video tutorial also gives a great explaination on the simulation code. My code running below:
3. Astronomy - SCI 238
I did learn Astronomy in High school. Idk why I wasn’t as amazed back then (probably since I was too focused on memorizing things for the exam). But also, I guess like most subjects, the more you think about it, the better you’d learn to appreciate it.
The course is a lot of calculations and thought experiments, and I’m just glad I’m not studying as an astrophysicist (or any sciences for that matter). They are up against understanding something way beyond anyone could imagine, understanding how nature works. Learning more of the universe is a humbling experience knowing that our humanity don’t matter at all. It will in the future disappear as our sun evolve into a red giant, like the rest of the billions of main sequence stars in the galaxy. Here are few of my favorite topics/chapters that really changed how I percieve our the universe:
A) Time
__ Time dilation __: Einstein discovered that nothing beats the speed of light and is constant. This implies many things, one of which if you go fast enough near light speeds, you’ll notice a phenomena called time-dilation (thought experiment: a really fast spaceship will see that light travel with a duration = distance/light-speed. But an outside observer will see that same light travel a longer distance. So to the observer, that light in the spaceship travel at longer duration and thus slower). Thus, at high speeds, time runs slower ⏱. This explains the twin paradox (if your twin make a high-speed journey into space, you will be much older when she returns). Note: you can’t travel back in time though.
__ Looking into the past __: Light travels about 10 trillion km a year. It’ll take ~1s for light to travel from the moon to our eyes, ~8 min for light to travel from the sun, and 2.5 million years from Andromeda galaxy - the closest galaxy to ours. But what’s even crazier is that this means the things we see are things in the past. If we predict the universe to be ~14 billion years old, than we won’t be able to see things further than 14 billion LY (lookback time). Not because there’s nothing. But it just means light hasn’t had time to reach us yet 🤯.
B) Spacetime & gravity & blackhole
After this course, when I see the term ‘gravity’ I now imagine a rubber sheet we call spacetime. Gravity isn’t really a force, but rather a curvature of this analogous rubber sheet, when a mass drops on the sheet and bends/distort its local geometry. The higher mass and the smaller the radius, the weight would stretch the rubber down even more. This explains orbiting of things around a higher mass object like the sun (imagine a smaller ball rolling around a hole).
This also helps illustrate the blackhole ⚫️, which is a high mass that you shrink insanely small until it stretches the spacetime to a bottomless pit (at that point, its escape velocity is the speed of light, so you can’t escape - nothing beats the speed of light). So falling into a black hole based on this analogy of spacetime rubber sheet, is ‘falling’ in its literal sense (it doesn’t however ‘suck in objects’). Just like trying to hit a golf ball down its cup, black hole is relatively small so unless it’s really close and your aim is really good, not everything will fall into it.
To detect gravitational wave, they build an entire 4km observatory (in multiple locations too) called LIGO. The LIGO consist of 2 arms, and when gravitational wave pass, one arm shortens and the other lengthen by a minuscule amount (smaller than size of atom!). When a faraway blackhole collapse or 2 neutron stars merge, you could detect this. Of course, because the detection is extremely subtle, they’d compare the result with another LIGO observatory elsewhere for validation.
C) The inevitable - Death of star and the death of us
Lifetime of our sun (main sequence star): starts from a dusty cloud (abundant in our galaxy) -> gravity will win over thermal pressure and the cloud contracts and spin into a protostar -> continue contracting until core is hot and fusion happens which release energy to stop the core from contracting -> now a main sequence star -> runs out of fuel and become red giant (the core shrinks and heats up further while the phrotosphere expand) -> Helium fusion begins and core start expanding again -> planetary nebula -> core is then left behind as a white dwarf (super dense - size of earth but with the mass of a star).
Where will humans end in that process? Earth (and even Mars that we’re trying to colonize) will probably be wiped out by the time our sun enters red giant phase. 😢. (assuming we survive from this deadly virus, global warming, or other social problems we currently have). Hey! we’re pretty screwed! 😱
D) The unknown
Other than detecting gravitational waves mentioned earlier, scientists study all sorts of things, from x-ray images, radio images, redshift of light from all sorts of interstellar objects, spectroscopy, gravitational lensing, luminosity, temperature, masses, quantum mechanics, etc. These are mostly indirect observations because there’s no way to instrument things directly. An image of the supermasive blackhole at the center of the galaxy, captured by combining multiple radio telescopes, were also a huge recent advancement in 2019.
There are however, a lot of unknowns. For example we know that the universe is expanding. What’s causing it to expand is this ‘dark energy’ which is estimated to make up 68% of the universe. Yet everything about this dark energy is still unknown to us. The other 27% is dark matter (undetected mass that affects gravity), and the normal matter (what we can observe with our instruments) only adds up to less than 5%. We’ve gone far and yet might not even be close to what the universe has to offer.🙀
I was planning to watch Interstellar (for my second time) after the term ends, but by the time of writing I’ve just finished a whole 3 season Attack on Titan marathon in one sitting. While fresh in mind, there are some quotes that resonates a lot with me (with regards to astronomy).
‘Nothing can supress human curioisty’ - Eren Jaeger
The fight for mankind’s survival against the titans, the curiosity for truth and what lies beyond their walls, the complacency of mankind no longer willing to fight after 100 years of being protected by the walls, while the main characters risk their lives to pursue change and break the hopeless odds of winning. Similar to the plot, I think space exploration is in essense not much different. In the scheme of things, there are probably more to know about the universe, but yet the small successes we had throughout the past centuries will add up and prove to be a huge leap of us potentially surviving what seems to be the inevitable end of our civilization. (being completely positive and hopeful 😛)
4. Quantum Mechanics - ECE 405
It was actually cool that at some point in the astronomy course, I was learning some facts about quantum tunneling (Particles can pop in/out of existence from vaccum and Stephen hawking believe it could help particles escape the black hole) or how quantum degeneracy pressure limits white dwarf from collapsing even further; I was able to understand a bit more and see the direct application of quantum mechanics as I was also taking this Quantum Mechanic course this term.
Quantum mechanics is the wierd science that will open up more new discoveries in the near future. I was quite excited in the beginning, but tbh right now I think I’m still as confused as I am before 😟.
The course follows the textbook ‘Quantum Mechanics’ by David H. Mcintyre. It was a pretty good book and I could understand the lectures more by reading the textbook. We simply covered till chapter 6 (out of 16 chapters), so it’s truly just the basics.
I learned how the quantum state is a superposition of states. Everytime we measure the system in one orientation, we will observe it being in a particular state, but at the same time it’ll disturb the state of the observable on other (imcompatible) orientations that had been measured prior. We represent a quantum state as a normalized vector (ket), and its operators/observables as matrices. With some quantum math, one could derive equations to predict the probability of observables, deriving the possible states the atoms could be at, predict the future of quantum system by solving the Hamiltonian equation, etc. All the concepts are summarized as the basic ‘postulates’.
There are lots of math, terminologies, and rules. It’s like learning physics for the first time all over again (a new kind of physics). I was able to apply the mathematical concepts on the exam questions, but I still struggle to gain real practical insights of it. It just hasn’t clicked yet for me.
As our final project for this course my group (team of 4) did a presentation on application of quantum mechanics for quantum clocks. The standard SI for 1 second is defined precisely by counting the frequency of oscillations of an excited Cesium atom - atomic clocks. To improve the precision and accuracy of our clocks, scientists had been experimenting different instruments to manipulate atoms in its quantum state and leveraging quantum entanglement. Measurement of accurate time will allow discoveries such as more accurate gps, high speed transmissions, synchoronization of distributed systems (covered in ECE454), or even helping astronomers detect gravitational affects and new instruments to detect dark matter!
5. Capstone Design Project - ECE 498B
Our final capstone project was building ‘RedLife’, a web app that monitors the mental health problems that are developing in the university subreddit. Our group trains a linear regression model with BOW (simple, gives the best accuracy and fast training time) to classify posts into a predefined mental health topic classes such as relationships, academics, coops… We batch process the data (new reddit posts) from a public API every 10 minutes, and the app will display the posts for users to monitor certain categories or navigate to the actual Reddit post.
I was so glad to be blessed with a great team for our capstone project. We distributed the work based on subsystems - ML subsystem, backend subsystem, ETL processes, Front-end subsystems. I was primarily in charge of backend subsystem and database design. It was very satisfying to see the different components come together pretty smoothly (deployed our services in GCloud).
On the demo day, the Tableu server crashes! (luckily our member Zabrina took precautions the day before and had recorded our demo for the prototype). But it was hilarious that the app chose to break on the day of presentation, of all times 🤪 (Murphy’s law).
In introspection, we recognized that a flaw in the FYDP was that it focuses on engineering design more than product management. Since we chose a supervisor outside of ECE, his suggestions and concerns had always been talking with our clients (the university councelors) and collecting user stories to make sure we’re solving the right problem. - of which we didn’t do and he was pretty disappointed with that.
See the online brochure: https://www.eng.uwaterloo.ca/2021-capstone-design/electrical-computer/participants-7/
Our Demo: https://www.youtube.com/watch?v=uTwvjNZ3aqM
6. What’s next?
I got the Shopify 8 months internship that I applied for (and thanks to my friend Bob for referring me 😉)! Starting May 10th. Even before starting, they’ve been super generous with their merch! I love how the company works real hard on promoting the best working condition for all their employees working from home. I’m getting the feeling like it’s a company I can really grow with. I’m also excited to learn Ruby/Rails even further, considering Shopify is one of the biggest contributors to the Ruby community.
I plan to write a post to close up my 5 years in Uni.
Watched 3 seasons of Attack on Titan. Planning to finish up with the manga. Also there’s a lot of manga and movies in my list that I wanted to catch up on.
Gonna get a new Kindle! I’ve been craving for things to read when I’m taking a break off my desk or taking a breather outside.