Imagine this.. you wish to curate websites. So the workflow goes: bookmark a site after you read them, tag it, then you have a feed of all your bookmarks filtered by tag that you can then embed in your site.
To do this, I would need to:
- save the url from my phone browser
- tag the url
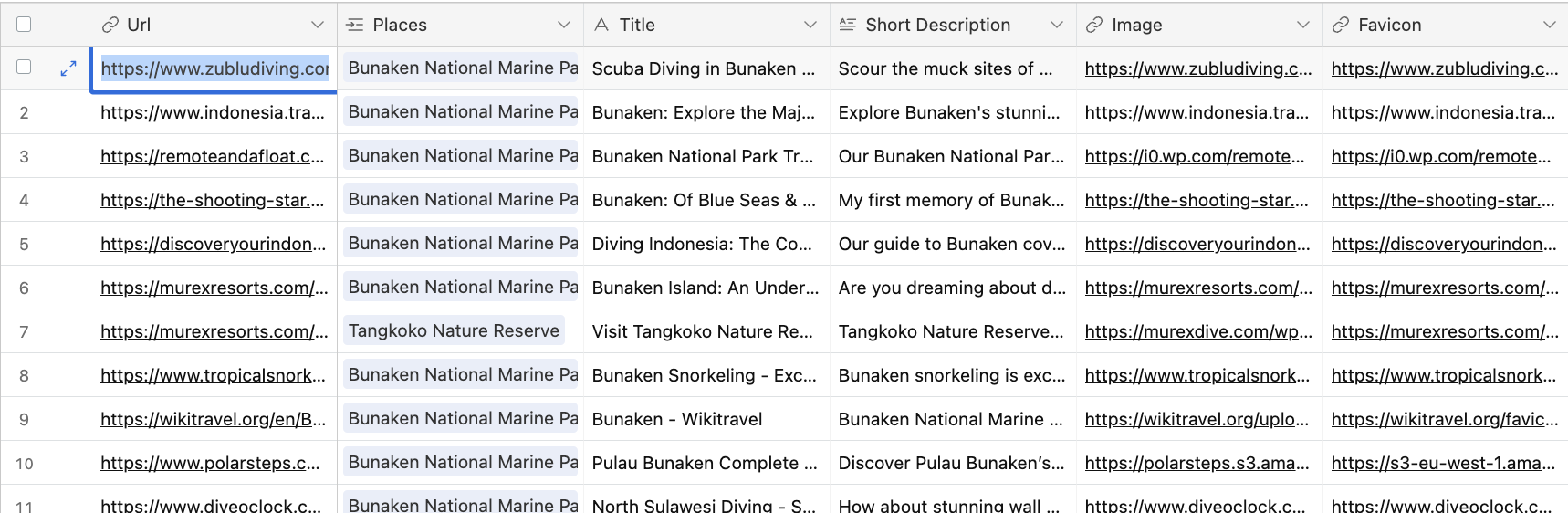
- extract and save images, title, short descriptions, favicon for the url
- generate a feed for the site
Straight forward isn’t it? It’s a bookmark + data enrichment step + feed generator. I’ve looked far and wide but couldn’t find a free solution (sorry for being cheap, but also embed.ly’s API cost $99. Excuse me?), so I decided to bootstrap it myself.
My workaround is:
- using Shortcuts to share websites to airtable from your phone (see my other article)
- manually tag the url in Airtable (use linked records)
- Scraping Solution! + update Airtable
- pull from Airtable and generate a view in the site
One solution for the scraping part: Diffbot
While writing this post I actually discovered Diffbot! They have a free version for 10k calls a month of 5 API calls per min. I quickly spun up a rake file that calls that API. Sample code:
response = Net::HTTP.get(URI("https://api.diffbot.com/v3/analyze?token=#{Rails.application.credentials.diffbot_token}&url=#{URI.encode_www_form_component(url)}")) details = JSON.parse(response) next if details.blank? || details["errorCode"] == 500 item[:Image] = details.dig("objects", 0, "images", 0, "url") item[:Favicon] = details.dig("objects", 0, "icon") item["Short Description"] = (details.dig("objects", 0, "text") || details.dig("objects", 0, "description"))&.split(/(?<=[.!?])\s+|\n+/)&.slice(2,2)&.join(" ")
For the most part that seem works as I expected - with a few caveats. First, it wasn’t able to resolve images with relative paths. Second, there doesn’t seem to be a description field out of the box. However, Diffbot lets you configure your own parsing rules, and I introduced ‘description’ field to look at all paragraph tags.
It was an easy solution, but still pretty clunky. I think I’ll keep using my original solution: a parser I bootstraped myself. But if I had discovered Diffbot earlier, I don’t think it’s worth bootstrapping my own scraper as it was good enough.
Original solution: Scrape it myself
Scraping for images/title/description is common yet isn’t straightforward because people just can’t agree on a protocol. Would make my life easier if all sites have their open-graph metadata set, with an absolute path to the image.
I didn’t want to build from scratch so I bootstraped from this code (krthush/link-preview) that generates link preview data (medium post by the author). I modified the front-end code such that it would query all URL records from airtable, call the API, and update the records with the enhanced data.
There were also tons of patches I made for it to work with the many edge cases.
- some images use data-src or data-orig-file instead of src attribute
- the original code only works for absolute path. I’ve had some image urls like /path_to_image which means I have to append that to the hostname, and there’s another url like ../../../image meaning I have to resolve the path to the image from the current url.
- the original code only looks at metadata to fetch description. But when websites don’t follow that rule, I’d fetch paragraph tags and get the first 2 sentences from it.
That codebase also had implemented bing image search in case they couldn’t get any good images from the site. Getting bing api key was a pain so I gave up on that idea.
As an alternative, this blogpost also had their own solution to generating link previews and I think it might be a better starting point if I was to start over and hadn’t spent my weekend doing this 😅.
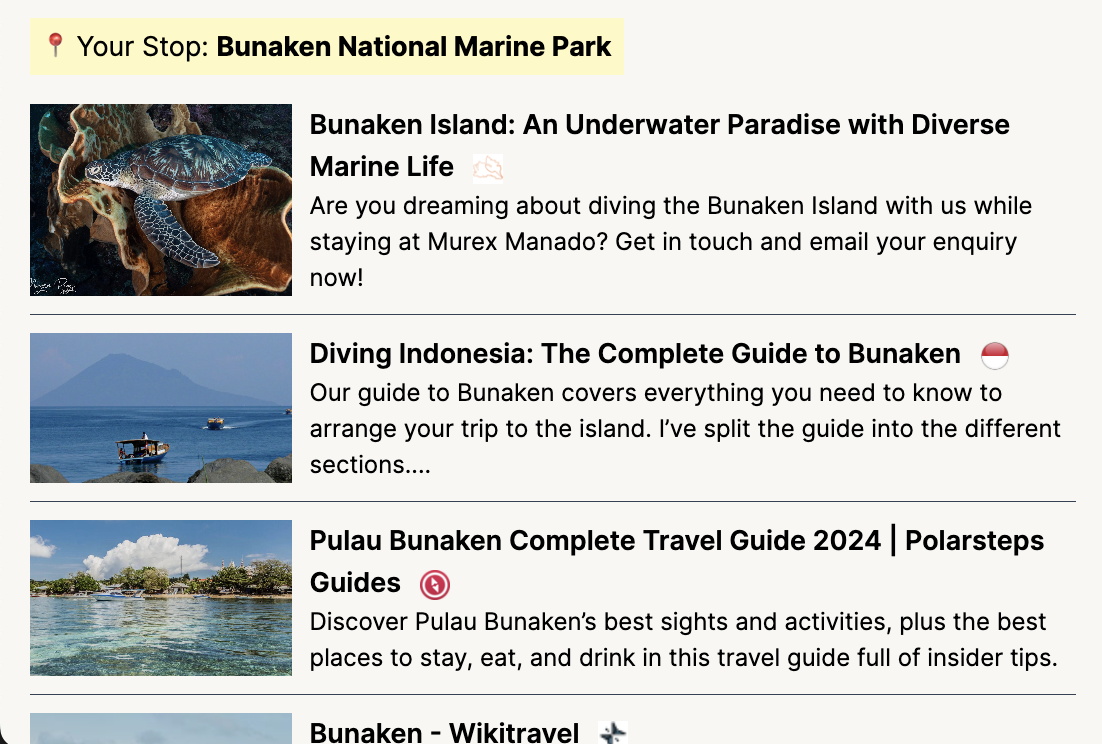
Preview of the feed I generated
Preview of the Airtable record ✨ enriched ✨